A First Look at Our CausalLM Omni Model: Previewing Our Intermediate Checkpoint to Partners
We are pleased to announce that an intermediate preview checkpoint of our CausalLM Omni model is now available to our strategic partners. This release constitutes an intermediate checkpoint of our ongoing pre-training phase, intended for partner evaluation while we continue the full training run toward a broader official release.
UNIFIED MULTIMODAL UNDERSTANDING AND GENERATION
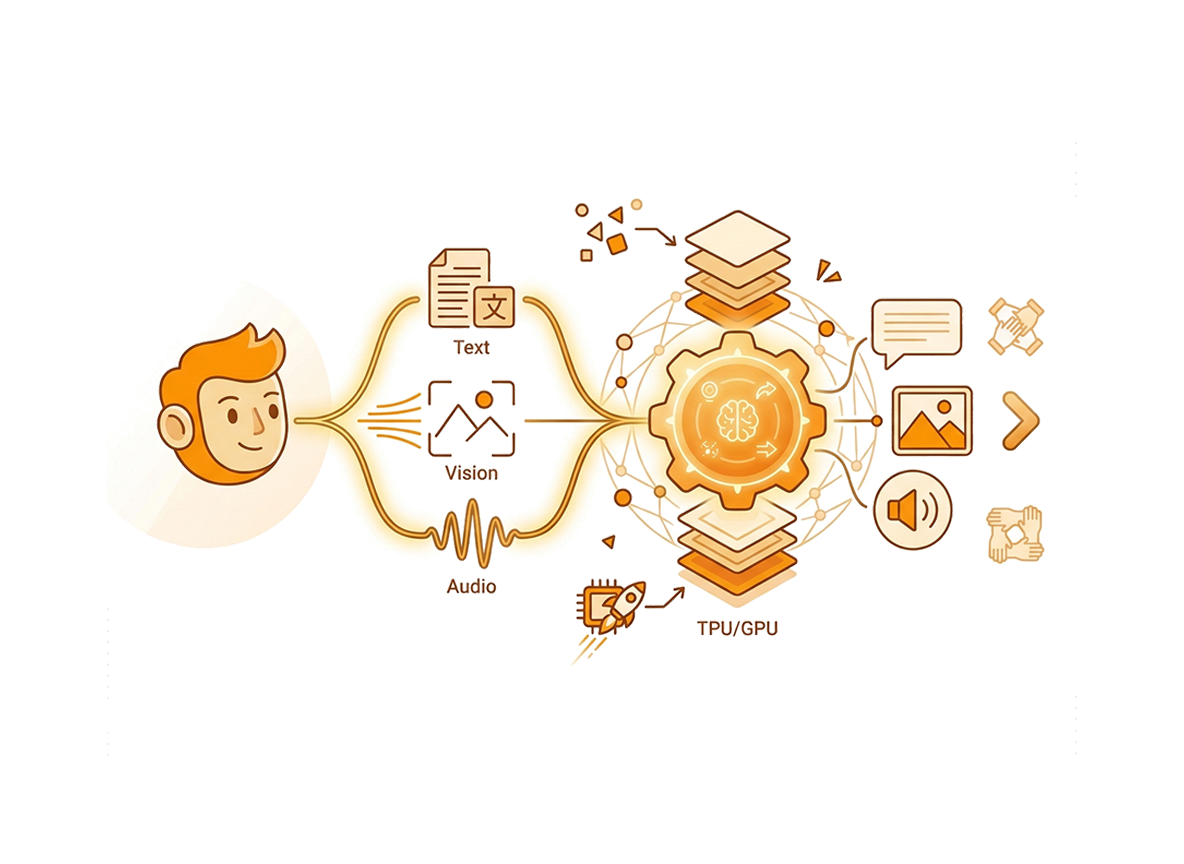
Built upon a highly optimized, standard Noam, Llama, and Qwen2-style foundational architecture, our 10-billion parameter dense model fundamentally reimagines how different data modalities are ingested and processed. It natively supports the unified understanding and generation of discrete images utilizing 16x and 32x compression rates, alongside discrete speech at an ultra-efficient 12.5Hz.
Unlike legacy MLLM systems that bolt disparate, modality-specific models together through complex bridging mechanisms, we designed CausalLM Omni to handle these diverse inputs and outputs as a single, continuous stream of one-dimensional tokens. For generative tasks spanning text, vision, and audio, our model generates an autoregressive output of semantic tokens. We subsequently decode these tokens utilizing advanced flow matching techniques, resulting in high-fidelity image and speech generation. This unified 1D token approach eliminates traditional cross-modal bottlenecks and preserves deep semantic alignment across all data types.
INNOVATIVE TRAINING PARADIGM AND SYNTHETIC DATA
This preview checkpoint represents an intermediate Base model that we have subjected to Supervised Fine-Tuning, transforming it into a highly capable Instruct model ready for complex partner deployments. We trained the Base model on a rigorous, high-density corpus of one trillion native, discrete multimodal mixed tokens. In a significant departure from traditional internet data scraping dependencies, we trained this model entirely on fully synthetic and distilled data. We curated this dataset to incorporate high-quality teacher logits distilled directly from leading open-source models, ensuring premium reasoning capabilities, reduced hallucination rates, and exceptional knowledge density.
Linguistically, our pre-training regimen focuses extensively on achieving deep mastery of four primary languages: English, Chinese, German, and Japanese. While we provide optimal, native-level support for nuanced generation and comprehension in these core languages, we also provide limited, functional support for a vast array of other global languages. This supplementary language capability adheres to a natural long-tail distribution pattern, highly comparable to the multilingual coverage observed in the OpenAI Whisper model's pre-training data.
ADVANCED TOKENIZATION STRATEGY
During our initial foundational pre-training phase, we uniquely processed the text modality using two distinct tokenizers simultaneously, allowing the network to capture a much broader and more resilient structural understanding of human language. However, to maximize instruction-following performance and operational efficiency in this specific preview version, our Supervised Fine-Tuning stage exclusively utilizes the robust Qwen2.x/3 Tokenizers.
We have heavily augmented this tokenization framework with a comprehensive multimodal vocabulary expansion, resulting in a massive total vocabulary size of 185,600 tokens capable of encapsulating complex visual and auditory concepts.
PROGRESSIVE CONTEXT SCALING AND HARDWARE EFFICIENCY
We employed a progressive pre-training methodology, systematically scaling the context length through carefully calibrated evolutionary stages: 4k, 32k, 128k, 256k, and ultimately reaching a massive 1-million token context window. This allows our model to digest entire knowledge bases, expansive document repositories, and long-form audio and video in a single inference pass.
To make this expansive context accessible and practical for real-world deployment, we deeply integrated Multi-Query Attention mechanisms. As a direct result of these architectural optimizations, the quantized version of our CausalLM Omni model can process the entire 1-million token context natively within just 24GB of VRAM, utilizing full attention mechanisms, without requiring any memory offloading.
Advanced compute infrastructure supported our development of the CausalLM Omni model. We executed the foundational pre-training using Jax on TPUv6e clusters. We conducted subsequent phases, including context length extension and supervised fine-tuning, on Nvidia A100 GPUs and TPUv4 systems, utilizing highly optimized custom kernels for maximum training efficiency.
FUTURE OUTLOOK
While this preview release offers a substantial and functional glimpse into the next-generation capabilities of our CausalLM Omni architecture, our core research team remains sharply focused on completing the full training cycle. Future iterations and the final official release will introduce expanded parallel streaming capabilities across modalities, a seamless, low-latency full-duplex conversational mode for natural real-time interaction, and significantly scaled-up training data to further enhance cognitive reasoning.
We encourage our strategic partners to begin testing the preview checkpoint immediately, as your telemetry and feedback will directly inform our final optimization and alignment phases for the CausalLM Omni project. We will release further announcements regarding public availability, comprehensive benchmarks, and expanded feature sets in due course.

