当社のCausalLM Omniモデルの初公開: パートナー向け中間チェックポイントのプレビュー
当社のCausalLM Omniモデルの中間プレビューチェックポイントが、戦略的パートナー向けに利用可能になったことをお知らせします。このリリースは、現在進行中の事前学習における中間のチェックポイントを構成しており、より広範な公式リリースに向けた完全な学習を継続しながら、パートナーによる評価を目的としています。
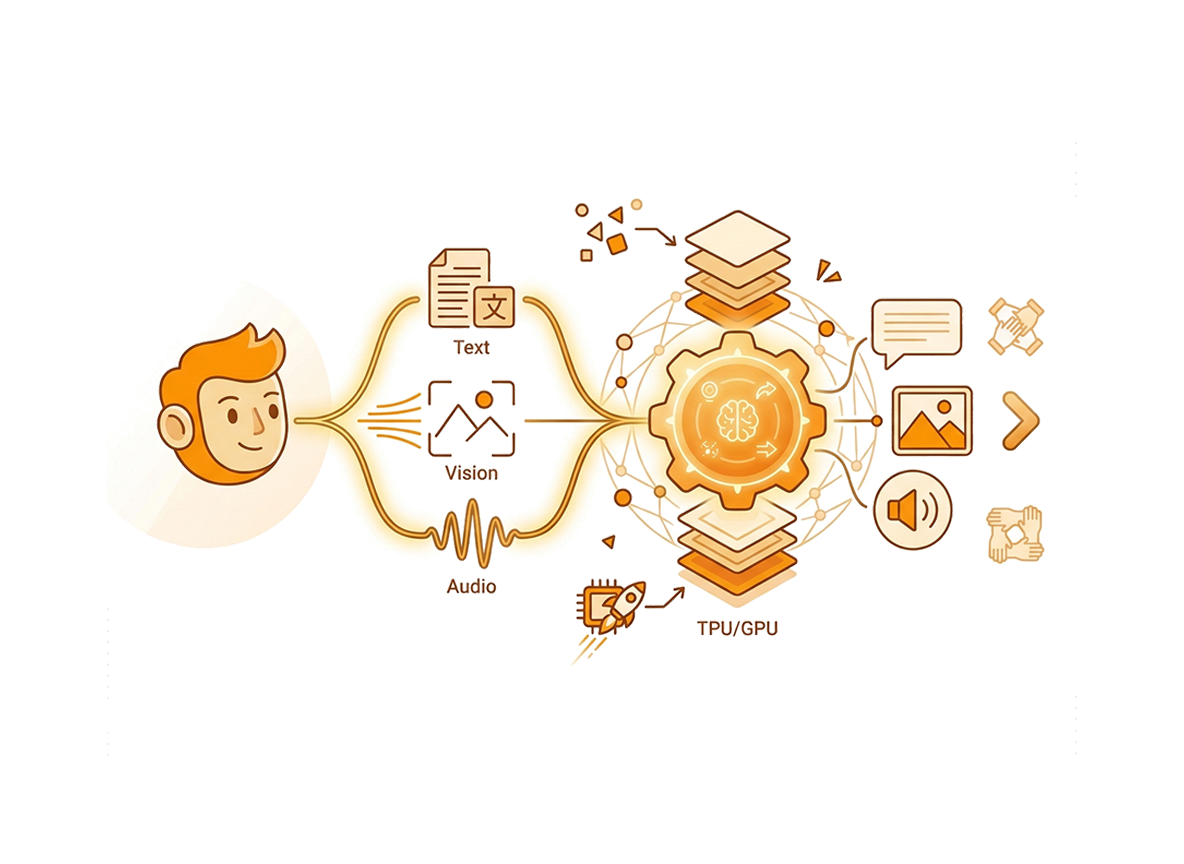
統合されたマルチモーダルの理解と生成
高度に最適化された、Noam、Llama、Qwen2スタイルの標準的な基盤アーキテクチャ上に構築された、当社の100億パラメータの密なモデルは、異なるデータモダリティがどのように取り込まれ処理されるかを根本的に再構築します。超高効率な12.5Hzでの離散的な音声に加えて、16倍および32倍の圧縮率を利用した離散的な画像の統合的な理解と生成をネイティブにサポートします。
複雑なブリッジメカニズムを通じて異なるモダリティ固有のモデルを一つに結合する従来のMLLMシステムとは異なり、CausalLM Omniはこれらの多様な入力と出力を、単一の連続した1次元トークンストリームとして処理するように設計されています。テキスト、ビジョン、オーディオにまたがる生成タスクにおいて、当社のモデルはセマンティックトークンの自己回帰出力を生成します。その後、高度なフロー・マッチング技術を用いてこれらのトークンをデコードし、忠実度の高い画像や音声を生成します。この統合された1Dトークンのアプローチは、従来のクロスモーダルのボトルネックを排除し、すべてのデータタイプ間で深い意味的整合性を保持します。
革新的な学習パラダイムと合成データ
このプレビュー・チェックポイントは、教師ありファインチューニングの対象となった中間のベースモデルであり、複雑なパートナーのデプロイの準備が整った強力なInstructモデルへと変換されています。私たちは、1兆のネイティブな離散マルチモーダル混合トークンから成る、厳密で高密度なコーパスでベースモデルを学習させました。
従来のインターネットのデータ・スクレイピングへの依存から大きく脱却し、私たちはこのモデルを完全に合成および抽出されたデータのみで学習させました。優れたオープンソースモデルから直接抽出された高品質な教師のロジットを組み込むようにこのデータセットをキュレートし、最高品質の推論能力、幻覚率の減少、そして並外れた知識密度を確保しています。
言語的には、当社の事前学習は、英語、中国語、ドイツ語、日本語という主要な4言語の深い習熟に集中的に取り組んでいます。これらのコア言語での細微な生成や理解について、ネイティブレベルでの最適なサポートを提供するとともに、その他広範な多様なグローバル言語にも限定的かつ機能的なサポートを提供します。この補足的な言語機能は、OpenAI Whisperモデルの事前学習データで観察される多言語カバレッジに匹敵する、自然なロングテール分布のパターンに従っています。
高度なトークン化戦略
初期の基礎的な事前学習の段階において、当社では他の模範とは異なり、2つの異なるトークナイザを同時にテキストモダリティの処理に使い、人間の言語におけるもっと広範で強固な構造的理解をネットワークに捕捉させました。しかし、今回の特定のプレビュー版において指示従属のパフォーマンスと操作効率を最大化するために、当社の教師ありファインチューニング段階では強固なQwen2.x/3 トークナイザだけを特別に使用しています。
このトークナイザフレームワークを、包括的なマルチモーダルの語彙の拡張によって大幅に増強しました。これにより、185,600という膨大な合計語彙サイズが実現し、複雑な視覚および聴覚の概念を捕捉することができます。
プログレッシブなコンテキストスケーリングとハードウェアの効率性
私たちは、慎重に調整された進化的段階である4k、32k、128k、256kを経由してコンテキストの長さをシステム的にスケーリングし、最終的に100万トークンという巨大なコンテキストウィンドウに到達する、段階的な事前学習方法を採用しました。これにより、当社のモデルは、単一の推論パスでナレッジベース全体や膨大なドキュメントリポジトリ、長時間におよぶ音声や動画を消化することができます。
この広範なコンテキストを現実世界のデプロイメントでアクセス可能かつ実用的にするために、Multi-Query Attentionメカニズムを深く統合しました。これらのアーキテクチャの最適化が直接もたらした結果として、量子化バージョンのCausalLM Omniモデルは、完全なAttentionメカニズムを利用して、メモリをオフロードすることなく、わずか24GBのVRAMで100万トークンのコンテキスト全体をネイティブ処理することが可能です。
高度なコンピューティングインフラストラクチャが、当社のCausalLM Omniモデルの開発を支えました。私たちは、TPUv6eクラスタ上のJaxを使用して基盤となる事前学習を実行しました。コンテキストの長さの拡張や教師ありのファインチューニングを含む後のフェーズについては、最大限の学習効率を得るために高度に最適化されたカスタムカーネルを利用して、Nvidia A100 GPUおよびTPUv4プラットフォーム上で実施しました。
今後の展望
今回のプレビュー公開により、当社のCausalLM Omniアーキテクチャの次世代機能の実用的かつ実質的な片鱗を提供できましたが、当社のコア研究チームは、完全な学習サイクルの完了に依然として鋭く照準を合わせています。今後のイテレーションおよび最終的な公式リリースでは、自然なリアルタイム対話に向けた、途切れがなく低遅延な全二重対話モード、モダリティにまたがる平行ストリーミング機能の拡張、認知推論をさらに高めるために大幅に拡大された学習データ導入する予定です。
皆さまのデータやフィードバックがCausalLM Omniプロジェクトの最終的な最適化や調整に直接活用されるため、戦略的パートナーの皆さまにおかれましては、プレビューのチェックポイントのテストにただちに着手いただくようお願いいたします。公開状況、総合的なベンチマーク、拡張機能セットに関するさらなるお知らせについては、今後順次発表する予定です。

