全面审视我们的CausalLM Omni模型:向合作伙伴预览我们的中间检查点
我们很高兴地宣布,我们的CausalLM Omni模型的一个中间预览评估点现在向我们的战略合作伙伴开放。此次发布构成了我们正在进行的预训练阶段的一个中间检查点,旨在供合作伙伴进行评估,同时我们将继续全面的训练过程,以期进行更广泛的正式发布。
统一的多模态理解与生成
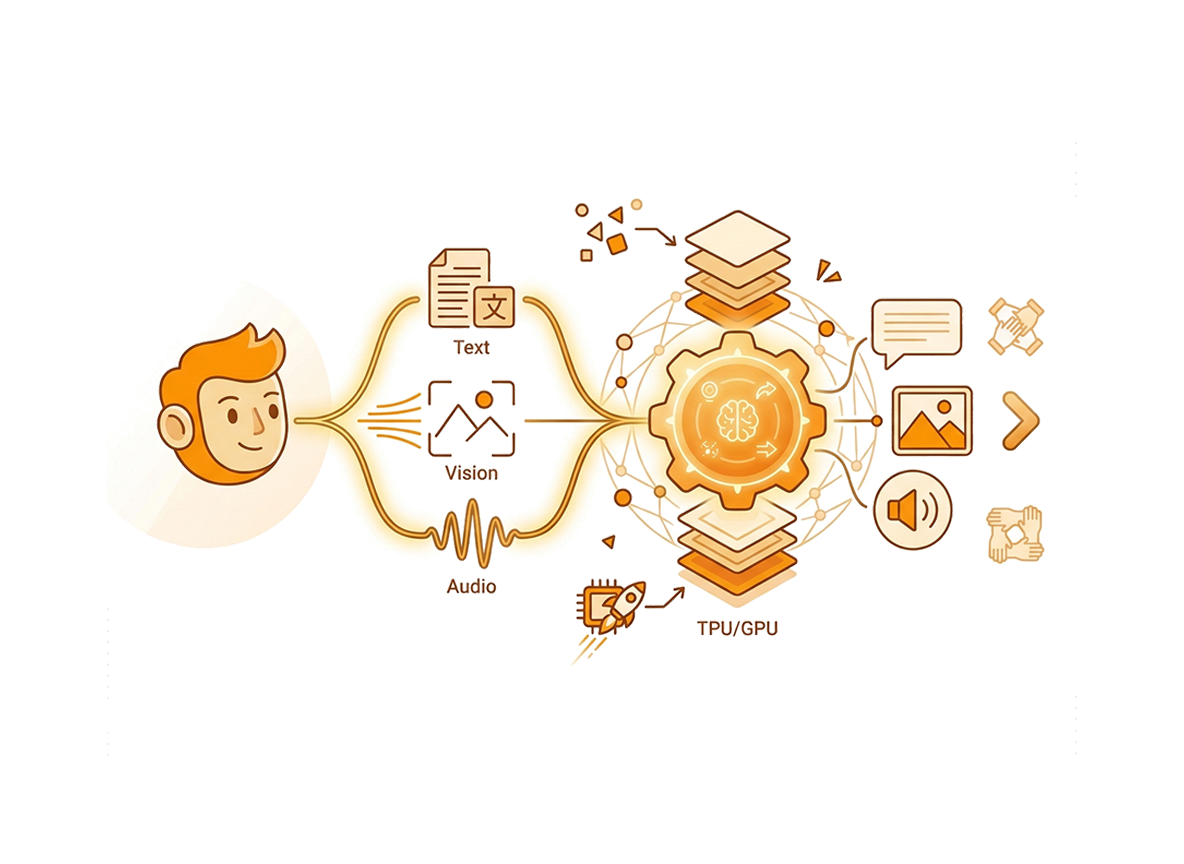
基于高度优化的标准Noam、Llama和Qwen2风格的基础架构,我们的100亿参数密集模型从根本上重新构想了不同数据模态的摄取和处理方式。它原生支持利用16倍和32倍压缩率进行离散图像的统一理解和生成,以及在超高效12.5Hz下的离散语音。
与通过复杂桥接机制将不同特定模式模型拼凑在一起的传统MLLM系统不同,我们设计的CausalLM Omni将这些不同的输入和输出作为一个单一、连续的一维token流来处理。对于涵盖文本、视觉和音频的生成任务,我们的模型生成语义token的自回归输出。随后,我们利用先进的流匹配技术解码这些token,从而实现高保真度的图像和语音生成。这种统一的一维token方法消除了传统的跨模态瓶颈,并保留了所有数据类型之间的深度语义对齐。
创新的训练范式和合成数据
这个预览检查点代表了一个中间的基础模型,我们对其进行了有监督微调,将其转变为一个能力极强的Instruct指令模型,准备好进行复杂的合作伙伴部署。我们在一个包含1万亿原生、离散多模态混合token的严格、高密度语料库上训练了该基础模型。
与传统对互联网数据抓取依赖的显著不同之处在于,我们完全在全合成和提取的数据上训练这个模型。我们精心策划了这个数据集,结合了直接从领先开源模型中提取的高质量教师逻辑logits,从而确保了卓越的推理能力、更低的幻觉率和出色的知识密度。
在语言方面,我们的预训练方案广泛专注于深入掌握四种主要语言:英语、中文、德语和日语。虽然我们为这些核心语言提供最佳的母语级别的细致生成和理解支持,但我们也为大量其他全球语言提供有限的、功能性的支持。这一补充性语言能力遵循自然的长尾分布模式,与OpenAI Whisper模型的预训练数据中观察到的多语言覆盖面高度可比。
高级标记化策略
在我们最初的基础预训练阶段,我们独特地同时使用两个不同的分词器来处理文本模态,使网络能够捕捉到对人类语言的更广泛和更有弹性的结构理解。然而,为了在这个特定的预览版本中最大化指令跟随性能和操作效率,我们的监督微调阶段专门利用了强大的Qwen2.x/3分词器。
我们通过全面的多模态词汇扩展对该标记化框架进行了极大的增强,从而产生了高达185,600个token的大规模总词汇量,能够封装复杂的视觉和听觉概念。
渐进式上下文扩展和硬件效率
我们采用了渐进式预训练方法,通过仔细校准的发展阶段系统地缩放上下文长度:4k、32k、128k、256k,并最终达到巨大的一百万token上下文窗口。这使我们的模型能够在单次推理通道中消化整个知识库、庞大的文档库以及长篇音频和视频。
为了使这个庞大的上下文能够被访问并在现实部署中实用,我们深度集成了多查询注意力 (Multi-Query Attention) 机制。作为这些架构优化的直接结果,我们CausalLM Omni模型的量化版本可以在仅24GB的VRAM中原生处理整个百万token上下文,利用完全的注意力机制,而无需任何内存卸载。
先进的计算基础设施支持了我们CausalLM Omni模型的开发。我们在TPUv6e集群上使用Jax执行了基础预训练。我们在Nvidia A100 GPU和TPUv4系统上进行了后续阶段的工作(包括上下文长度扩展和有监督微调),利用高度优化的自定义内核以获得最大训练效率。
未来展望
虽然此预览版本为我们CausalLM Omni架构的下一代功能提供了实质性和功能性的展示,但我们的核心研究团队仍然坚定地专注于完成完整的训练周期。未来的迭代版本和最终正式版本将引入跨模态的扩展并行流传输能力、用于自然实时交互的无缝低延迟全双工对话模式,以及用于进一步增强认知推理的显著扩展的训练数据。
我们鼓励我们的战略合作伙伴立即开始测试该预览检查点,因为您的遥测及反馈将直接通报给我们在CausalLM Omni项目中的最终优化和对齐阶段。我们将在适当的时候发布有关公开可用性、全面基准测试和扩展功能集的进一步公告。

