Ein erster Blick auf unser CausalLM Omni Modell: Vorschau unseres Zwischen-Checkpoints für Partner
Wir freuen uns, Ihnen mitteilen zu können, dass ab sofort ein Zwischenvorschau-Checkpoint unseres Modells CausalLM Omni für unsere strategischen Partner verfügbar ist. Diese Veröffentlichung stellt einen Zwischen-Checkpoint unserer laufenden Pre-Training-Phase dar, der für Partner-Evaluationen gedacht ist, während wir den vollständigen Trainingslauf in Richtung einer breiteren offiziellen Veröffentlichung fortsetzen.
VEREINHEITLICHTES MULTIMODALES VERSTÄNDNIS UND GENERIERUNG
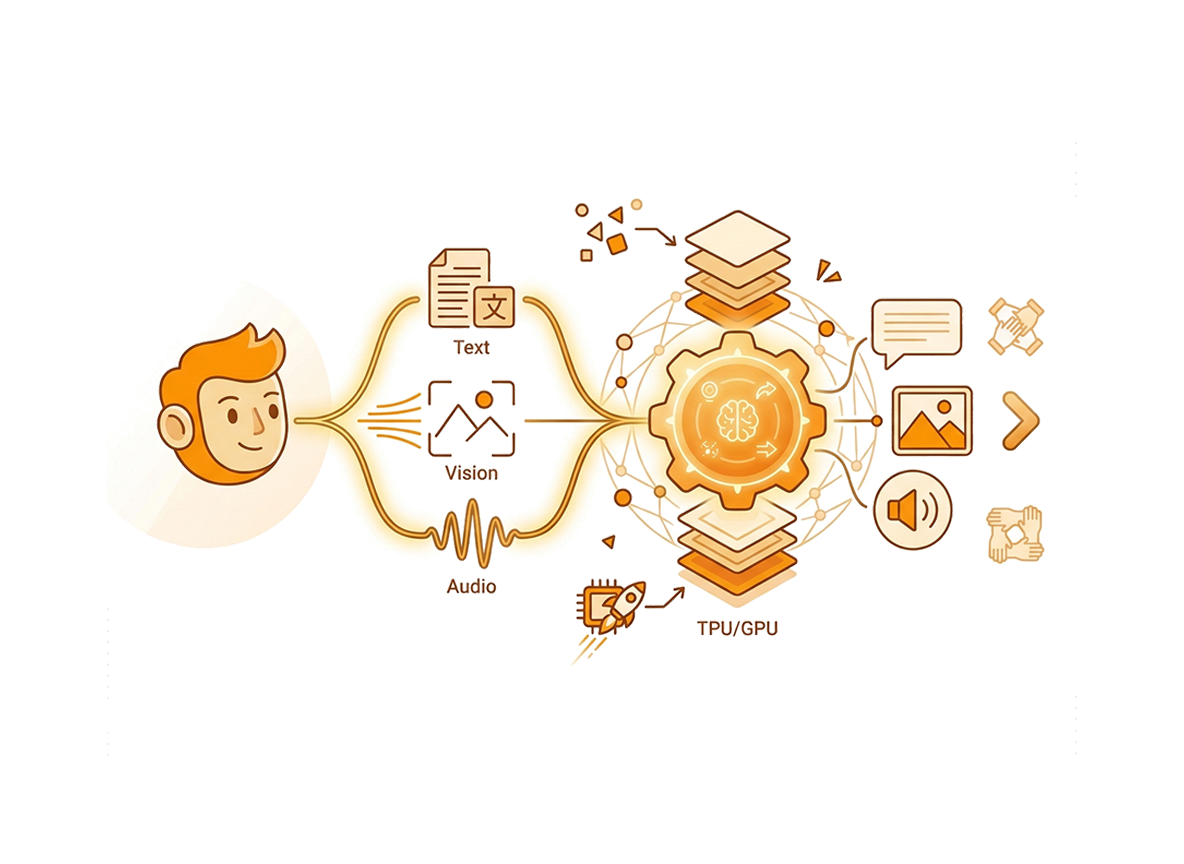
Aufbauend auf einer hochgradig optimierten, standardmäßigen Basisarchitektur im Noam-, Llama- und Qwen2-Stil wird mit unserem dichten Modell von 10 Milliarden Parametern von Grund auf neu gedacht, wie verschiedene Datenmodalitäten aufgenommen und verarbeitet werden. Es unterstützt nativ das einheitliche Verständnis sowie die Generierung von diskreten Bildern bei Kompressionsraten von 16x und 32x, neben diskreter Sprache bei ultra-effizienten 12,5 Hz.
Im Gegensatz zu älteren MLLM-Systemen, die durch komplexe Brückenmechanismen verschiedene modalitätsspezifische Modelle miteinander verbinden, haben wir CausalLM Omni so konzipiert, dass diese vielfältigen Ein- und Ausgaben als einzelner, kontinuierlicher Strom kognitiver, eindimensionaler Token verarbeitet werden. Für generative Aufgaben, welche Text, Bild und Audio umfassen, generiert unser Modell eine autoregressive Ausgabe von semantischen Token. Anschließend decodieren wir diese Token mittels fortschrittlicher Flow-Matching-Techniken, was zu einer Bild- und Sprachausgabe von hoher Genauigkeit führt. Dieser vereinheitlichte Ansatz mit 1D-Token eliminiert herkömmliche cross-modale Engpässe und bewahrt die tiefe semantische Ausrichtung über alle Datentypen hinweg.
INNOVATIVES TRAININGS-PARADIGMA UND SYNTHETISCHE DATEN
Dieser Vorschaue-Checkpoint stellt ein zwischengeschaltetes Basismodell dar, das wir einem "Supervised Fine-Tuning" unterzogen haben, um es in ein hochleistungsfähiges Instruct-Modell zu transformieren, das bereit für komplexe Partner-Einsätze ist. Wir trainierten das Basismodell an einem strikten und dichten Korpus von einer Billion nativen, diskreten, gemischten multimodalen Token.
In einer signifikanten Abkehr von herkömmlichen Abhängigkeiten vom Internet-Daten-Scraping trainierten wir dieses Modell vollständig an völlig synthetischen und destillierten Daten. Wir kuratierten diesen Datensatz so, dass er hochwertige Teacher-Logits beinhaltet, die direkt von führenden Open-Source-Modellen destilliert wurden und garantieren so erstklassige Schlussfolgerungsfähigkeiten, reduzierte Halluzinationsraten sowie außergewöhnliche Wissensdichte.
In sprachlicher Hinsicht konzentrieren wir uns bei unseren Vortrainingsbemühungen umfassend darauf, die tiefe Beherrschung dieser vier Hauptsprachen zu erzielen: Englisch, Chinesisch, Deutsch und Japanisch. Während wir in diesen Kernsprachen die optimale Unterstützung bei der differenzierten Generierung und beim Verständnis auf Muttersprachler-Niveau erbringen, leisten wir außerdem limitierte und funktionelle Unterstützung bei weitreichenden anderen globalen Sprachen. Diese zusätzliche Sprachfähigkeit folgt einem natürlichen Long-Tail-Verteilungsmuster, das in hohem Maße mit der mehrsprachigen Deckung vergleichbar ist, die bei den Vortrainingsdaten für das Modell OpenAI Whisper beobachtet wurde.
ERWEITERTE TOKENISIERUNGS-STRATEGIE
Während unserer ersten grundlegenden Vortrainingsphase verarbeiteten wir die Textmodalität einzigartig unter Verwendung von zwei verschiedenen Tokenizers, um es dem Netzwerk zu ermöglichen ein erheblich breiteres und belastbareres strukturelles Begreifen menschlicher Sprachen zu erfassen. Jedoch stützt sich unsere SFT - Phase („Supervised Fine-Tuning SFT“) ausschließlich auf die robusten Qwen2.x/3 Tokenizers, um hierbei in der spezifischen Vorschauversion die Performanz den Einsatzanweisungen folgend und in Kombination mit betrieblicher Effizienz bestmöglich zu maximieren.
Wir verstärkten diesen Tokenisierungsrahmen sehr aufwendig mit einer umfassenden Ausweitung zum multimodalen Vokabular und bekamen auf diese Weise als Ergebnis bei der Erfassung von verknüpften optischen und akustischen Aspekten eine unermessliche Gesamtanzahl von Vokabeln mit 185,600 Token.
PROGRESSIVE KONTEXTSKALIERUNG UND HARDWAREZUVORLÄSSIGKEIT
Wir nutzten beim Vortrainieren eine schrittweise durchgehende Methode und skalierten den Kontextbereich systematisch durch genau dosierte Evolutionsschritte ab: von 4k, 32k, 128k, 256k auf schlussendlich zu einem Kontextfenster bis hoch in unglaubliche Dimensionen im Rahmen von 1 Million an Token. Dadurch wird unser Modul für die Zusammenfassung sämtlicher Wissensgrundlagen und großer Schriftstückbestände befähigt, während darüber hinaus lange Ton- und Bildausgaben in nur einem Vorgang möglich sind.
Wir haben komplexe „Multi-Query-Attentions“-Mechanismen tiefgehend eingegliedert, um den Zugang dieses sich ins Weite erstreckenden Kontextspektrums für das Arbeiten an reellen Anwendungen praktischer gestaltbar zu verwirklichen. Als direktes Resultat für die Optimierung in den Architekturen kann diese quantitative Anwendung als Ausführung von dem CausalLM Omni-Model nativ in nicht mehr als einzig allein innerhalb eines Speichers voll VRAM-24GB sämtliche Verarbeitungsverläufe im 1 Millionen Umfang und in Kontexten der Token für das komplette Aufmerksamkeitssystem und gänzlich unverzögert bewältigt bekommen, so auch dann ganz ohne ein „Memories-Offloading“ erforderlich ist.
Die fortschrittlichen Rechneranlagen unterstützten unser Vorankommen betreffs CausalLM Omni- Model-Schöpfung. Wir absolvierten basierend auf Jax am TPUv6e Knotenkreis ein grundierendes Basisvorbereitungsprogramm. Auch für die Erweiterung im Kontextlängenbereich und mit Begleitung vom Beaufsichtigungs Feintunings-System realisierten wir für maximale Ausbildungsökonomie nachgestellte Sequenzen mit Einsatz Nvidia A100 GPUs u. TPUv4s Anlagen mithilfe stark verbesserter Einzelkernenfunktionen.
ZUKÜNFTIGER AUSBLICK
Während Ihnen dieser als Preview zugänglich gemachte Checkpoint ein wesentliches Bild und in der Funktion zu agierenden Bereichen Einblick bzgl. Leistungen unserer Architekturen künftiger CausalLM Omní-Entwicklungen vermittelt, verbleibt parallel das Team unser Wissenschaftszentrale klar dabei fokussiert alle Ausbildungszyklen nun in der Komplettheit voranzubringen. Künftige Entwicklungsabschnitte u. sowie dann auch offizielle Neuerscheinungen bringen über die Parameter hin in der Multimodialität zur Realzeit-Wechselvernetzung als reale ungebundene Dialogform das Duplex-Sprechen gänzlich in Echtzeit und mit massiv anwachsendem Erweiterungsvermögen für das Datenausbildungswesen inklusive, sodann den Fokus an kognitiver Begründbarkeit massig anhebend - dann auch ohne Ruckeln ins Netz integriert – weit gestreut noch mit fortlaufend mehreren Ausgabemerkmalen parallel verlaufend ausgedehnt neu dazu auf.
Es wäre erfreulich für uns wenn die Anwender unter unseren strategischen Partnerschaften umgehend beginnen am Testbetrieb des Checkpoint-Models zur Preview-Erprobung tätig zu sein da hiermit Ihre Feedback und Telemetrie Daten ganz konkret den Endlauf unserer Verbesserungsphase an Angleichungen fürs Omni CausalLM –Projekt fundiert aussagekräftig unterstützen werden. Für uns wird es dazu gegebenen Momentum an Ankündigungen folgen - etwa hinsichtlich zu allgemeinen Öffentlichkeiten, breite Testberichte der Basen - nebst um weitere funktionell-bedienbare Einstellungsfunktionen noch folgend an Bekanntmachung gesendetes zu finden!

